17 :orange_book: Cross-validation
To overcome the challenges of train/test split, we can use cross-validation. It consists of repeating the procedure such that the training and testing sets are different each time.
Generalization performance metrics are collected for each repetition and then aggregated. As a result we can assess the variability of our measure of the model’s generalization performance.
Note that there exists several cross-validation strategies, each of them defines how to repeat the fit/score procedure. In this section, we will use the K-fold strategy: the entire dataset is split into K partitions. The fit/score procedure is repeated K times where at each iteration K - 1 partitions are used to fit the model and 1 partition is used to score.
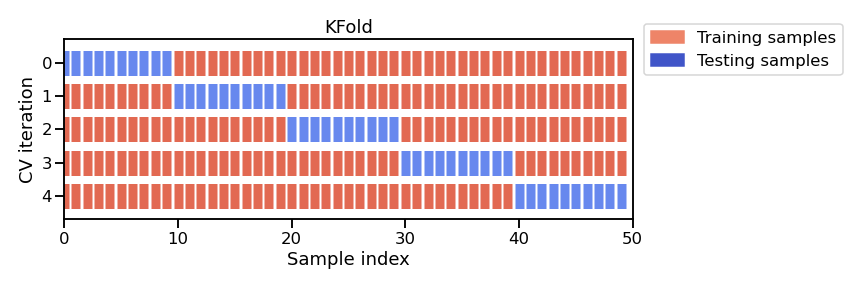
This figure shows the particular case of K-fold cross-validation strategy. For each cross-validation split, the procedure trains a clone of model on all the red samples and evaluate the score of the model on the blue samples. As mentioned earlier, there is a variety of different cross-validation strategies. Some of these aspects will be covered in more detail in future notebooks.
Cross-validation is therefore computationally intensive because it requires training several models instead of one.
Question
Cross-validation allows us to:
a) train the model faster
b) measure the generalization performance of the model
c) reach better generalization performance
d) estimate the variability of the generalization scoreSelect all answers that apply